【Python3】ホスト検知ツールを作ったらバイトオーダーの理解が深まった話
こんにちは。ctfを始めたくてハリネズミ本を買いました。
今回は「サイバーセキュリティプログラミング Pythonで学ぶハッカーの思考」という本を図書館で借りたのでそれの第3章にあるネットワークスニッファーを作ってみました。途中バイトオーダー絡みの話に苦労したのでそれも書きます。
参考にした本、環境

参考というかほぼ一緒です。ただこの本はpython2系で書かれています。本記事ではpython3.6に置き直して記述します。
なおホストOSはMac OS X Sierra、プロセッサはIntelのi5(x86のプロセッサ)です。windowsホストだとプロミスキャスモードに関する記述がいるようです。その辺りもこの本には書いてありますが、本記事では省略します。
ソースコード
#!/usr/bin/env python3 import socket import struct from ctypes import * import threading import time from netaddr import IPNetwork, IPAddress # スニッファーのIPアドレスと属するネットワークのアドレス host1 = "133.50.69.136" host1_subnet = "133.50.69.0/24" host2 = "192.168.11.2" host2_subnet = "192.168.11.0/24" host = host2 subnet = host2_subnet magic_message = b"SAPPORO" # UDPデータグラム送信用関数 **[2]** def udp_sender(subnet, magic_message): time.sleep(5) # ブロードキャスト用のソケット sender = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) for ip in IPNetwork(subnet): try: sender.sendto(magic_message, (str(ip), 65212)) except Exception: pass # IPヘッダを受け取る構造体 **[4]** class IP(Structure): _fields_ = [ # ホストがリトルエンディアンの場合。ビッグエンディアンだとihlとversionの順序が逆転する ("ihl", c_uint8, 4), ("version", c_uint8, 4), ("tos", c_uint8), ("len", c_uint16), ("id", c_uint16), ("offset", c_uint16), ("ttl", c_uint8), ("protocol_num", c_uint8), ("sum", c_uint16), ("src", c_uint32), ("dst", c_uint32), ] def __new__(cls, socket_buffer=None): return cls.from_buffer_copy(socket_buffer) def __init__(self, socket_buffer=None): self.protocol_map = {1:"ICMP", 6:"TCP", 17:"UDP"} self.src_address = socket.inet_ntoa(struct.pack("<L", self.src)) self.dst_address = socket.inet_ntoa(struct.pack("<L", self.dst)) # マップを使い可読なプロトコル名称にする try: self.protocol = self.protocol_map[self.protocol_num] except: self.protocol = str(self.protocol_num) # ICMPレスポンスを受け取る構造体 **[5]** class ICMP(Structure): _fields_ = [ ("type", c_uint8), ("code", c_uint8), ("checksum", c_uint16), ("unused", c_uint16), ("next_hop_mtu", c_uint16) ] def __new__(cls, socket_buffer): return cls.from_buffer_copy(socket_buffer) def __init__(self, socket_buffer): pass # **[1]** socket_protocol = socket.IPPROTO_ICMP sniffer = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket_protocol) sniffer.bind((host, 0)) #キャプチャ結果にIPヘッダを含める sniffer.setsockopt(socket.IPPROTO_IP, socket.IP_HDRINCL, 1) #パケットの送信開始 **[2]** t = threading.Thread(target=udp_sender, args=(subnet, magic_message)) t.start() try: while True: # パケットの読み込み **[3]** raw_buffer = sniffer.recvfrom(65565)[0] # **[4]** ip_header = IP(raw_buffer[0:20]) # ICMPであれば処理 if ip_header.protocol == "ICMP": offset = ip_header.ihl * 4 # IPヘッダの終わりからICMPヘッダの最後まで切り取る buf = raw_buffer[offset:offset + sizeof(ICMP)] # **[5]** icmp_header = ICMP(buf) # コードとタイプが3かチェック **[6]** if icmp_header.code == 3 and icmp_header.type == 3: # 標的サブネットに存在するか if IPAddress(ip_header.src_address) in IPNetwork(subnet): # **[7]** if raw_buffer[len(raw_buffer)-len(magic_message):] == magic_message: print("Host Up: {}".format(ip_header.src_address)) pass except KeyboardInterrupt: sniffer.close()
解説
ほとんどの部分が上の書籍と一緒なので詳しい説明はそれを参照してください。ざっと処理を説明します。[番号]は上のソースコードのコメントにあるものと対応します。
[1] rowソケットを用いてホストマシンをネットワークにバインドさせてレスポンスを受け取れるようにする。
[2] UDPパケットをネットワーク全体に送る。その時このプログラムから送信されたパケットであることを証明するmagic messageを同時に送る。
[3] ネットワークの各ノードがUDPパケットに対してICMPメッセージを返してくるのでそれを受信する。
[4] ICMPにはIPヘッダが上位20バイトに付与される。それを切り取りCライクな構造体に変換する。
[5] IPヘッダにはICMPメッセージが続くのでそれを切り取り同様にCライクな構造体に変換する。
[6] 閉じたポートに対するUDPパケットにはコードとタイプのフィールドが3であるICMPレスポンスを返してくるのでそれをチェック
[7] 先ほどのmagic messageはレスポンスの末尾につけられて返されるのでそれをチェック
上の書籍と違う点はsocketのsendやrecvにバイト型が利用されるため、文字列を送信したいときは"メッセージ".encode()やb"メッセージ"とする必要がある点です。
githubにも**[1]**などのコメントがないソースコードをあげています。
https://github.com/teru01/network-sniffer
実行結果

こんな感じですね。実行するにはsudoが必要です。ちなみに192.168.11.4はwindowsなのですが、windowsファイアウォールを無効にしなければレスポンスは返ってきませんでした。デフォルトのFW設定ではICMPを遮断するらしく、ICMPを利用するpingも通らないようです。
本題
タイトルにあるバイトオーダーの話をします。これで結構悩んだので。
IPv4のwikipedia(https://ja.wikipedia.org/wiki/IPv4)を見ると、IPヘッダはバージョン、ヘッダ長、サービス種別・・・のような順番で並んでいます。しかし上のソースコードのIPクラスを見ると"version"(バージョン)と"ihl"(ヘッダ長)の順番だけが逆転しています。これは何故なのでしょうか。答えは「バイトオーダー」と「ビットナンバリング」にあります。
バイトオーダー
コンピューダはデータをバイト単位でメモリに展開して管理します。このとき、メモリ上でのバイト列の並び方を「バイトオーダー」と言います。バイトオーダーは大別して2種類あり、バイト列がメモリアドレスの小さい方から大きい方へ並ぶ「ビッグエンディアン」、逆にメモリアドレスの大きい方から小さい方へ並ぶ「リトルエンディアン」に分けられます。ネットワークを流れるデータはビッグエンディアン、対して現在多くのPCで採用されているx86ではリトルエンディアンを使用しています。つまりネットワークを流れてきたデータを受け取り処理する際はバイトオーダーの違いに注意する必要があるということです。
ビットナンバリング
1バイトは8ビット、つまり1つのメモリ領域は8つのビット領域を持つことになります。データのビット列の最下位(Least Significant Bit)がビットアドレス0番に配置されるものをLSBゼロビットナンバリング、逆にビット列の最上位(Most Significant Bit)がビットアドレス0番に配置されるものをMSBゼロビットナンバリングと言います。x86ではLSBゼロビットナンバリングを採用しています。以下の画像では青部分がLSB、オレンジがMSBとなっています。
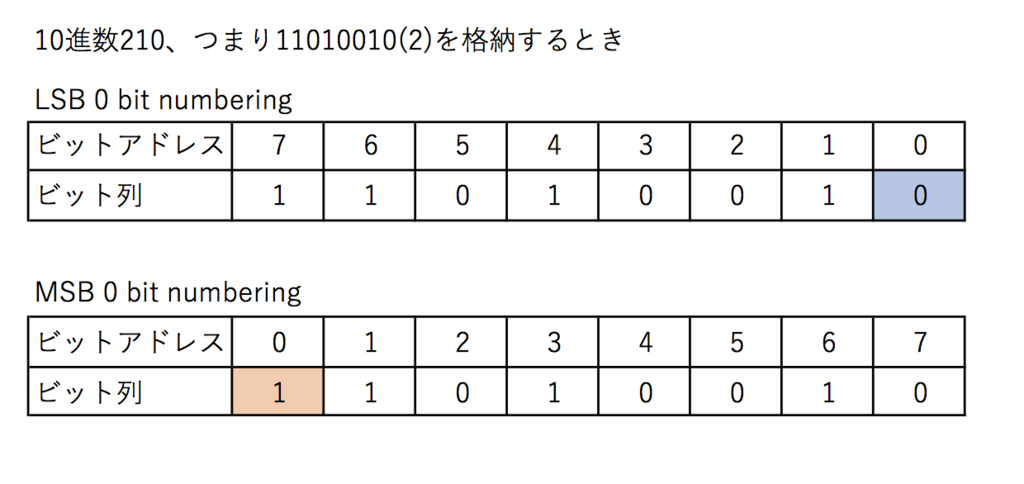
*訂正 2017/6/27 画像のエンディアンが間違えていました。
versionとihlが逆転する理由
以上のことを踏まえると、以下のような説明がつきます。太い罫線で囲まれた領域を1バイトとしています。

まず、IPヘッダがパケットとして流入してきて、それをrecvfromによりバイト単位で受け取ります。メモリ(ホスト)と書いてあるのはraw_bufferのことです。ホストマシンはリトルエンディアンなのでデータがメモリ領域の後ろから順に書き込まれ、それを構造体にダンプします。構造体はフィールドを定義した順番通りに隣接してメモリ領域が確保されるので、図のような並びになります。x86ではLSBゼロビットナンバリングなので、4ビットごとに区切った場合下位側にあるIHLが構造体のihlフィールドとして先に読み込まれます。
まとめ
ネットワークとホストPCでのバイトオーダは異なる。特にビット単位で扱うときは要注意。
頑張って調べたのですが上の説明は誤りがある可能性があります。そこが違うよっていう人はぜひコメントください。
あとLAN内のiPhoneはICMPレスポンスを返すのですが最後尾がb'y\xfe\xbc\x00\x0f\x00\x00'となってmagic messageと異なるため検知できませんでした。何故でしょう・・・?